
Products
GG网络技术分享 2025-03-18 16:14 0
我有一个Dataframe
df = pd.DataFrame({'content':['A Name:[MINSDDL], Code:[KRKN]','A Name:[LAVRION]','C:[ANGELA]','C:[KUMASI]']})
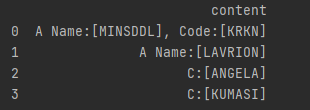
我想要用正则表达式的方法 提取Code:[] ; A Name:[] ; C:[] 里面的值
结果像这样子
import pandas as pdimport re
def fun(se):
r1 = re.findall(r'Code:\\[(.*?)\\]', se['content'])
if r1 == []:
r1 = ['']
r2 = re.findall(r'A Name:\\[(.*?)\\]', se['content'])
if r2 == []:
r2 = ['']
r3 = re.findall(r'C:\\[(.*?)\\]', se['content'])
if r3 == []:
r3 = ['']
return r1[0], r2[0], r3[0]
df = pd.DataFrame({'content':['A Name:[MINSDDL], Code:[KRKN]','A Name:[LAVRION]','C:[ANGELA]','C:[KUMASI]']})
print(df)
df[['B', 'C', 'D']] = df.apply(fun, axis = 1, result_type='expand')
print(df)
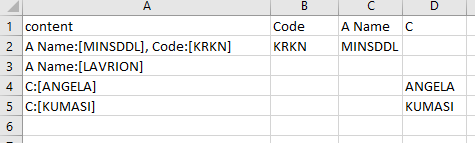
'''--result
content
0 A Name:[MINSDDL], Code:[KRKN]
1 A Name:[LAVRION]
2 C:[ANGELA]
3 C:[KUMASI]
content B C D
0 A Name:[MINSDDL], Code:[KRKN] KRKN MINSDDL
1 A Name:[LAVRION] LAVRION
2 C:[ANGELA] ANGELA
3 C:[KUMASI] KUMASI
'''最近在MOOC上学习嵩天老师的《Python网络爬虫与信息提取》,非常好的一门课程。相比互联网上其他爬虫教程,这门课的优势在于系统性。该课程用较短的时间介绍了入门爬虫的知识点,并辅以实例练习,帮助学习者快速搭建起一个爬虫的知识框架。 此为正则表达式部分的课程笔记。 正则表达式(regular expression),简称 regex,或 RE,是用来简洁表达一组字符串的表达式,是一种通用的字符串表达框架。正则表达式可用一行字符串来表达有限或无限个字符串的特征。在网络爬虫的过程中,可以在解析好的网页文本中搜索满足一定特征的字符串。 文中的部分图片来自嵩天老师的课程课件截图。
正则表达式语句就是由这些操作符组合而成的。上述操作符右侧的实例,说明了该操作符的简单用法。在实际应用中,需要结合实际场景,通过各种操作符的组合来编写出正则表达式。以下是一些应用正则表达式的经典案例,理解这些案例,有助于你更好地理解正则表达式操作符的用法。
RE库是python中用来解析正则表达式的库。 调用方式:import re
fpath = r"c:\\program",在python中等价于fpath = "c:\\\\program"。用此方法使得字符串表达更简洁。Demand feedback
